J’ai donné pour la deuxième année consécutive le TD du cours d’optimisation convexe de première année des Mines Paris. J’ai écrit quelques notes pour aider les étudiants à visualiser les théorèmes du cours. Elles peuvent peut-être en aider d’autres… À lire en restant vigilant, car c’est un domaine où je ne suis qu’un amateur (dans les deux sens du terme : de celui qui débute, et de celui qui apprécie — double sens auquel m’a initié Denis Bernard, mon directeur de thèse) . J’ai pas mal utilisé les méthodes d’optimisation (surtout dans le cas différentiable et sans contrainte) pour ma recherche, mais je n’ai appris la théorie (et les cas plus fins, par exemple non différentiables) essentiellement qu’avec ces TD. Pour ceux qui veulent aller plus loin que ces notes ultra basiques, le mieux est de jeter un œil à Numerical Optimization de Nocedal et Wright.
I put a first postdoc offer on Inspire a few days ago. I am looking for smart independent people, who are ideally willing to push the use of tensor network methods in quantum field theory.
The application has a very close deadline in the advertisement, so that I can make offers to candidates in sync with the standard high energy theory postdoc cycle (to which I was only partly familiar with a few days ago). If you are interested and cannot assemble all the documents by the deadline, feel free to contact me and to apply still. If you really arrive too late, I will open another postdoc position later, still funded by the ERC.
It is now official: the ERC awarded me generous research funding to work on the intersection of tensor networks and quantum field theory (see e.g. here). The proposal that got me the money is here and, as far as I am concerned, it is public (I will be happy if you can solve the open problems faster than my collaborators and I). Some formal job openings will follow but you can already check the “working with me” section.
Soon, I will have to work. But now I thank the people who helped me. Thanks to those who proofread my proposal and pushed me to apply (in particular Pierre Rouchon). Thanks also to Jean-Pierre Banatre who helped me prepare for the interview. Thanks to Mathieu Reboul at Armines who took care of the admin part and allowed me to focus on the science. Thanks, to the UK for leaving the ERC, which apparently allowed my project to go from “recommended for funding” to “funded“. Thanks finally to randomness — whether it comes from the splitting of many worlds, the collapse of the wave function, or the last digits of the Bohmian positions at the beginning of time — it certainly helped me.
I am at the Erwin Schrödinger Institute in Vienna for 1 more week, where I get a perfusion of tensor networks straight into my veins. There, I unsurprisingly talked about my recent work on continuous matrix product states. The blackboard talk was recorded, but sadly I wrote a little too small so I have to squint to read the equations. It is adapted to an audience knowing tensor networks very well, but quantum field theory slightly less.
To have more things to discuss at the breaks, I put on arxiv the results of my exploration of the ground state of the Sinh-Gordon model with relativistic continuous matrix product state. This is not a final version (some references are missing, and I will likely update the discussion), but I had to put it online at some point. I spent quite a lot of time optimizing the numerics but at the end still couldn’t fully settle the situation of the model near its self dual point. I still think the data is interesting nonetheless: it is obtained in the thermodynamic limit, and is fairly precise for moderate coupling. I hope it will also push people to develop better contraction routines, as ramping up the bond dimension could be enough to clarify the matter (at least numerically, before mathematical physicists and mathematicians nail it).
update: this position is now filled, but there will be new PhD and postdoc offerings very soon, on similar topics.
———–
I am now looking for a PhD student to work with me, starting next year (December 2022 at the latest). I have the money, I just need a smart person. The ideal topic, described in more detail in the offer below, would be tensor networks and their use in non-perturbative quantum field theory. However, I am open to inquiries on any other of my past subjects, so if there is something you are interested in, feel free to contact me!
The best is to start with an internship, to get a feel for the subject. This is why it is important to contact me asap if you’re interested, even before the offer is formally advertised on the website of the école doctorale.
1- Since October 4th, I am back in Paris with a position at Mines Paristech, which is a French “grande école” part of Paris Science et Lettres (PSL). I am also a member of the Quantic group, which is a joint venture with Inria and École Normale Supérieure exploring superconducting circuits for quantum information processing (theoretically and experimentally). I am very happy about this move back to Paris after 5 great years in Munich where I learned immensely and became more of an “adult” theoretical physicist. In Paris I will keep an interest in my old subjects: quantum field theory with variational methods, many body physics, quantum foundations (and others..). But I will try to develop tighter connection between state compression methods (tensor networks) and what is done in the group especially with cat qubits and error correction. For all these subjects, I will probably have some money soon from various sources. Students interested in any of these themes (even the exotic stuff) should feel free to contact me in advance to discuss possible PhDs or internships.
2- I gave a rather conceptual talk on collapse models at the Quantum Boundaries workshop. The talk was recorded:
3- For those who are in Paris, I will speak at Foundation 2020(which was delayed because of covid) on Thursday October 28th. I will present our latest results with Howard Wiseman on the equivalence between non-Markovian collapse models and Bohmian theories (this preprint).
For the European Tensor Network school 2021 at ICCUB in Barcelona, I started to write some lecture notes on continuous tensor network states. So far they cover only continuous matrix product states, which is a pretty stabilized subject. I tried to make them very detailed about the computations which can be scary for beginners. I plan (or rather hope) to extend the notes to include more recent developments like relativistic extensions in 1 space dimension, and non-relativistic extensions in 2 space dimensions and more.
J’ai discuté il y a quelques jours avec Vincent Debierre (du podcast Libaca) du problème de l’unification (ou de la jonction) entre modèle standard et gravité. J’ai surtout essayé de clarifier la logique : qu’est-ce qu’on cherche à faire, qu’est-ce qui est a priori possible et qu’est-ce qui ne l’est pas ?
Pour ceux qui peuvent passer outre ma grammaire floue et mon élocution un peu non-linéaire, c’est un moyen d’avoir une idée de ce domaine d’un point de vue peut-être hétérodoxe. Je suis aussi preneur de commentaires éventuellement critiques sur la présentation du problème, car je ne suis évidemment pas sans biais.
À la fin, je mentionne aussi les réseaux de tenseurs. C’est une nouvelle méthode pour résoudre numériquement des modèles existants difficiles (et non un nouveau modèle de la nature) qui est assez à la mode et qui m’occupe aujourd’hui davantage que la gravité. Je suis curieux de savoir si la philosophie en est compréhensible en quelques phrases.
Today I put online a major update of my pair of papers on the variational method for quantum field theory (short here, long here). The idea is still to use the same class of variational wave functions (relativistic continuous matrix product states) to find the ground state of (so far bosonic) quantum field theories in 1+1 dimensions. The novelty comes from the algorithm I now use to compute expectation values, that has a cost only proportional to where is the bond dimension. Using backpropagation techniques, the cost of computing the gradient of observables with respect to the parameters is also only . This is basically the same asymptotic scaling as standard continuous matrix product states.
Previously, the method was a nice theoretical advance as it worked without any cutoff, but it was not numerically competitive compared to bruteforce discretization + standard tensor methods (at least not competitive for most observables insensitive to the UV). With the new algorithm with improved scaling, I can go fairly easily from to , which gives relative error for the renormalized energy density at a coupling of order 1. Crucially, the error really seems to decrease exponentially as a function of the bond dimension, and thus with only a slightly higher numerical effort (say 100 times more) one could probably get close to machine precision. Already at relative error for the renormalized energy density, that is a quantity where the leading lattice contribution has been subtracted, I doubt methods relying on a discretization can compete. This makes me a bit more confident that methods working directly in the continuum are a promising way forward even if only for numerics.
Energy density and relative error for theory with RCMPS. RHT is the state-of-the-art renormalized Hamiltonian truncation result which is manifestly less precise
Now, let me go a bit more into the technicalities. Computing expectation values of local functions of the field with such a low cost seems difficult at first because the ansatz is not written in terms of local functions of . Naively this should at the very least square the cost to . The main idea to obtain the cheap scaling is to realize that the expectation value of vertex operators, i.e. operators of the form , can be computed by solving an ordinary differential equation (ODE) where the generator has a cost . Basically, computing vertex operators for relativistic CMPS is as expensive as computing field expectation values for standard non-translation-invariant CMPS. To solve this ODE, one can use powerful method with extremely quickly decaying errors as a function of the discretization step (e.g. very high order Runge-Kutta). So vertex operators are, in fact cheap. But local powers of the field are merely differentials of vertex operators, and thus can be computed as well for the same cost. Finally, to get the gradient, one can differentiate through the ODE with backpropagation, and obtain the result for only twice the cost. This allows the full variational optimization for all well-defined bosonic Hamiltonians with polynomial and exponential potentials.
There are 2 recent preprints on tensor networks I found interesting.
The first is Collective Monte Carlo updates through tensor network renormalization(arxiv:2104.13264) by Miguel Frias-Perez, Michael Marien, David Perez Garcia, Mari Carmen Banuls and Sofyan Iblisdir. I am certainly a bit biased because two authors come from our group at MPQ, and I heard about the result twice in seminars, but I think it is a genuinely new and interesting use of tensor networks. The main idea is to reduce the rejection rate of Markov Chain Monte Carlo (MCMC) by crudely estimating the probability distribution to be sampled from with tensor network renormalization. This combines the advantage of the Monte Carlo method (it is exact asymptotically, but slow especially for frustrated systems) with the advantage of tensor renormalization (it is very fast for approximations).
A quick word of caution for purists, technically they use the tensor renormalization group (TRG), which is the simplest approximate contraction method for 2d tensor networks. Tensor network renormalization (TNR) can refer to a specific (and more subtle) renormalization method introduced by Evenbly and Vidal (arxiv:1412.0732) that is in fact closer to what the Wilsonian RG does. This is just a matter of terminology.
Terminology aside, it seems the hybrid Monte Carlo method they obtain is dramatically faster than standard algorithms, at least in number of steps to thermalize the Markov chain (which remains of order 1 even for reasonably low bond dimensions). These steps are however necessarily more costly than for typical methods because sampling from the approximate distribution generated with TRG gets increasingly expensive as the bond dimension increases. As a result, for a large frustrated system, it is not clear to me how much faster the method can be in true computing time. I think in the future it would be really interesting to have a benchmark to see if the method can crush the most competitive Markov chain heuristics on genuine hard problems, like spin glasses or hard spheres for example. It is known that TRG struggles to get precise results for such frustrated problems, and so the approximation will surely degrade. But perhaps there is a sweet spot where the crude approximation with TRG (of high but manageable bond dimension) is sufficient to have a rejection rate in the MCMC at 10^(-4) instead of 10^(-15) for other methods in a hard-to-sample phase.
The second one is Entanglement scaling for by Bram Vanhecke, Frank Verstraete, and Karel Van Acoleyen. I am of course interested because it is on , my favorite toy theory of relativistic quantum field theory. There are many ways to solve this non-trivial theory numerically, and I really find them all interesting. Recently, I explored ways to work straight in the continuum, which is the most robust or rigorous perhaps, but so far not the most efficient for most observables.
So far, the most efficient method is to discretize the model, use the most powerful lattice tensor techniques to solve it, and then extrapolate the results to the continuum limit. The extrapolation step is crucial. Indeed, such relativistic field theories are free conformal field theories at short distance. This implies that for a fixed error, the bond dimension of the tensor representation (and thus the computational cost) explodes as the lattice spacing goes to zero. One can take the lattice spacing small, but not arbitrarily small.
With Clément Delcamp, we explored this strategy in the most naive way. We had used a very powerful and to some extent subtle algorithm (tensor network renormalization with graph independent local truncation, aka GILT-TNR) to solve the lattice theory. We pushed the bond dimension to the max that could run on our cluster, plotted 10 points and extrapolated. At the smallest lattice spacing, we were already very close to the real continuum theory, and a fairly easy 1-dimensional fit with 3 parameters gave us accurate continuum limit results. A crucial parameter for theory is the value of the critical coupling , and our estimate was . We estimated it naively: by putting our lattice models exactly criticality, and extrapolating the line of results to the continuum limit. This was in 2020, and back then this was the best estimate. It was the best because of the exceptional accuracy of GILT-TNR, which allowed us to simulate well systems even near criticality, and allowed us to go closer to the continuum limit than Monte Carlo people.
Extrapolation of the critical coupling as the lattice spacing (lambda is a proxy for it here) goes to zero in our paper with Clément.
Bram Vanhecke and collaborators follow a philosophically different strategy. They use an arguably simpler method to solve the lattice theory, boundary matrix product states. Compared to GILT-TNR, this method is simpler but a priori less efficient to solve an exactly critical problem. But, spoiler, they ultimately get better estimates of the critical coupling than we did. How is that possible? Instead of simulating exactly the critical theory with the highest possible bond dimensions, the authors simulate many points away from criticality and with different bond dimension (see image below). Then they use an hypothesis about how the results should scale as a function of the bond dimension and distance from criticality. This allows them to fit the whole theory manifold around the critical point without ever simulating it. This approach is much more data driven in a way. It swallows the bullet that some form of extrapolation is going to be needed anyway and turns it into an advantage. Since the extrapolation is done with respect to more parameters (not just lattice spacing), the whole manifold of models is fitted instead of simply a critical line. This gives the fit more rigidity. By putting sufficiently many points, which are cheap to get since they are not exactly at criticality or with maximal D, one can get high precision estimates. They find , which if their error estimate is correct, is about 1 and a half digits better than our earlier estimate (which is a posteriori confirmed, since the new result is about 1 standard deviation away from the mean we had proposed).
The points sampled by Bram Vanhecke et al around the critical line (also for different bond dimensions not shown)
Naturally, an extrapolation is only as good as the hypothesis one has for the functional form of the fit. There, I like to hope that our earlier paper with Clément helped. By looking at the critical scaling as a function of the lattice spacing, and going closer to the continuum limit than before, we could see that the best fit clearly contained logarithms and was not just a very high order polynomial (see above). I think it was the first time one could be 100 % sure that such non-obvious log corrections existed (previous Monte Carlo papers had ruled it out after suspecting it), the left no doubt. Interestingly, Bram and his Ghent collaborators had tried their smart extrapolations techniques back in 2019 (arxiv:1907.08603) but their ansatz for the functional form of the critical coupling as a function of the lattice spacing was polynomial. As a result their estimates looked precise, between 11.06 and 11.07, but were in fact underestimating the true value (like almost all papers in the literature did).
Could this scaling have been found theoretically? Perhaps. In this new paper, Vanhecke and collaborators provide a perturbative justification. My understanding (which may be updated) is that such a derivation is only a hint of the functional form because the critical point is deep in the non-perturbative regime and thus all diagrams contribute with a comparable weight. For example, individual log contributions from infinitely many diagrams could get re-summed into polynomial ones, e.g. non-perturbatively. In any case, I think (or rather hope…) that precise but “less extrapolated” methods will remain complementary and even guide the hypothesis for more data driven estimates.
In the end, congratulations to Bram, Frank, and Karel for holding the critical crown now. I will dearly miss it, and the bar is now so high that I am not sure we can contest it…
 where
where  is the bond dimension. Using backpropagation techniques, the cost of computing the gradient of observables with respect to the parameters is also only
is the bond dimension. Using backpropagation techniques, the cost of computing the gradient of observables with respect to the parameters is also only 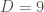 to
to 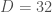 , which gives
, which gives  relative error for the renormalized energy density at a coupling of order 1. Crucially, the error really seems to decrease exponentially as a function of the bond dimension, and thus with only a slightly higher numerical effort (say 100 times more) one could probably get close to machine precision. Already at
relative error for the renormalized energy density at a coupling of order 1. Crucially, the error really seems to decrease exponentially as a function of the bond dimension, and thus with only a slightly higher numerical effort (say 100 times more) one could probably get close to machine precision. Already at 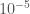 relative error for the renormalized energy density, that is a quantity where the leading lattice contribution has been subtracted, I doubt methods relying on a discretization can compete. This makes me a bit more confident that methods working directly in the continuum are a promising way forward even if only for numerics.
relative error for the renormalized energy density, that is a quantity where the leading lattice contribution has been subtracted, I doubt methods relying on a discretization can compete. This makes me a bit more confident that methods working directly in the continuum are a promising way forward even if only for numerics.
 theory with RCMPS. RHT is the state-of-the-art renormalized Hamiltonian truncation result which is manifestly less precise
theory with RCMPS. RHT is the state-of-the-art renormalized Hamiltonian truncation result which is manifestly less precise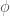 with such a low cost
with such a low cost 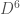 . The main idea to obtain the cheap scaling is to realize that the expectation value of vertex operators, i.e. operators of the form
. The main idea to obtain the cheap scaling is to realize that the expectation value of vertex operators, i.e. operators of the form  , can be computed by solving an ordinary differential equation (ODE) where the generator has a cost
, can be computed by solving an ordinary differential equation (ODE) where the generator has a cost 
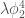 by Bram Vanhecke, Frank Verstraete, and Karel Van Acoleyen. I am of course interested because it is on
by Bram Vanhecke, Frank Verstraete, and Karel Van Acoleyen. I am of course interested because it is on  , my favorite toy theory of relativistic quantum field theory. There are many ways to solve this non-trivial theory numerically, and I really find them all interesting. Recently, I explored ways to work straight in the continuum, which is the most robust or rigorous perhaps, but so far not the most efficient for most observables.
, my favorite toy theory of relativistic quantum field theory. There are many ways to solve this non-trivial theory numerically, and I really find them all interesting. Recently, I explored ways to work straight in the continuum, which is the most robust or rigorous perhaps, but so far not the most efficient for most observables.  , and our estimate was
, and our estimate was  . We estimated it naively: by putting our lattice models exactly criticality, and extrapolating the line of results to the continuum limit. This was in 2020, and back then this was the best estimate. It was the best because of the exceptional accuracy of GILT-TNR, which allowed us to simulate well systems even near criticality, and allowed us to go closer to the continuum limit than Monte Carlo people.
. We estimated it naively: by putting our lattice models exactly criticality, and extrapolating the line of results to the continuum limit. This was in 2020, and back then this was the best estimate. It was the best because of the exceptional accuracy of GILT-TNR, which allowed us to simulate well systems even near criticality, and allowed us to go closer to the continuum limit than Monte Carlo people.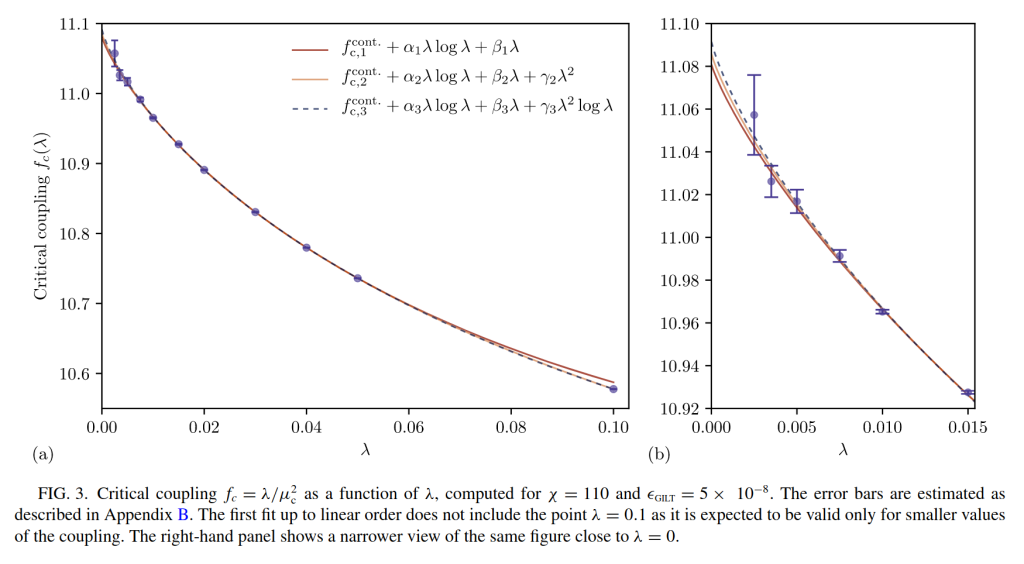
 , which if their error estimate is correct, is about 1 and a half digits better than our earlier estimate (which is a posteriori confirmed, since the new result is about 1 standard deviation away from the mean we had proposed).
, which if their error estimate is correct, is about 1 and a half digits better than our earlier estimate (which is a posteriori confirmed, since the new result is about 1 standard deviation away from the mean we had proposed). 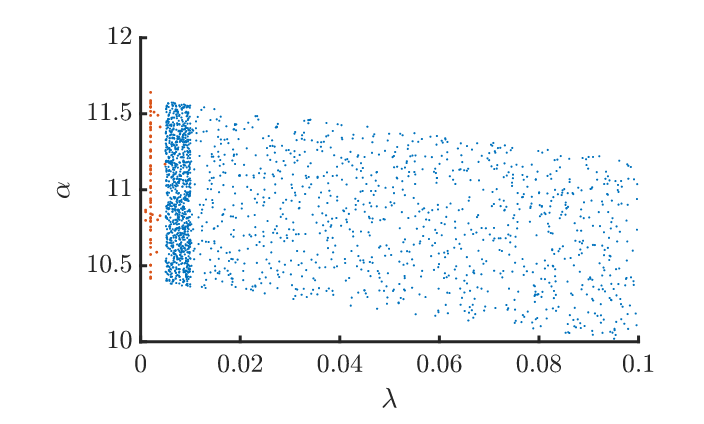
 left no doubt. Interestingly, Bram and his Ghent collaborators had tried their smart extrapolations techniques back in 2019 (
left no doubt. Interestingly, Bram and his Ghent collaborators had tried their smart extrapolations techniques back in 2019 ( non-perturbatively. In any case, I think (or rather hope…) that precise but “less extrapolated” methods will remain complementary and even guide the hypothesis for more data driven estimates.
non-perturbatively. In any case, I think (or rather hope…) that precise but “less extrapolated” methods will remain complementary and even guide the hypothesis for more data driven estimates.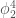 crown now. I will dearly miss it, and the bar is now so high that I am not sure we can contest it…
crown now. I will dearly miss it, and the bar is now so high that I am not sure we can contest it…